随着当下Serverless、FaaS生态的不断发展以及小程序的空前繁荣,越来越多的企业和个人用户把自己的应用,小程序部署到腾讯云无服务器云函数平台上,但随之而来的FaaS场景下高并发、大规模、快速启动等需求也给我们带来了巨大的挑战。为此我们打造了新一代Severless函数计算平台,在安全、可用性、性能上进行了全面升级。
新平台使用腾讯云自研的轻量级虚拟化技术,MicroVm启动时间缩短至90毫秒,函数冷启动减低至200毫秒,并且支持上万台计算节点同时扩容。同时在函数与VPC网络打通中,依托于新的隧道方案,时间也由原来的秒级降低至毫秒级。
注:文章整理自腾讯云专家工程师周维跃及腾讯云高级工程师李艳博在Kubecon 2019上的分享,原分享主题为《加速:无服务器平台中的冷启动优化》,本篇文章主要分享云函数冷启动优化实践,下篇文章将分享云函数访问VPC网络方面的优化。

文章内容主要分为三部分,首先介绍腾讯云函数的架构设计,其次看看函数的冷启动是如何产生的,以及冷启动包含哪些过程,最后分享腾讯云函数的一些优化方向方法。
腾讯云函数架构设计
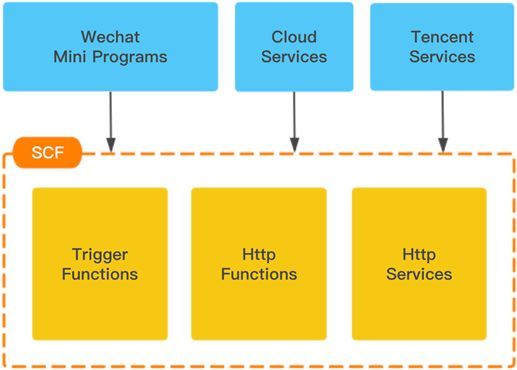
腾讯云函数SCF目前提供传统的事件触发器函数、HTTP调用函数以及HTTP web服务三种业务场景的支持,支撑着海量的微信小程序的运行、公有云快速增长的业务、以及腾讯自身的业务上云运行。微信小程序开发者从传统的主机,容器部署后段业务迁移到函数计算,在一个IDE开发环境中完成前后端业务的部署,极大的提高了小程序的研发效率。
因此我们也面临了非常多的挑战,比如多业务场景多租户的安全隔离,高并发的函数实例扩缩容,百万级别函数实例的集群管理,以及几十毫秒级别的冷启动延时,对于一些活跃函数的使用需要通过调度的能力解决冷启动的问题。
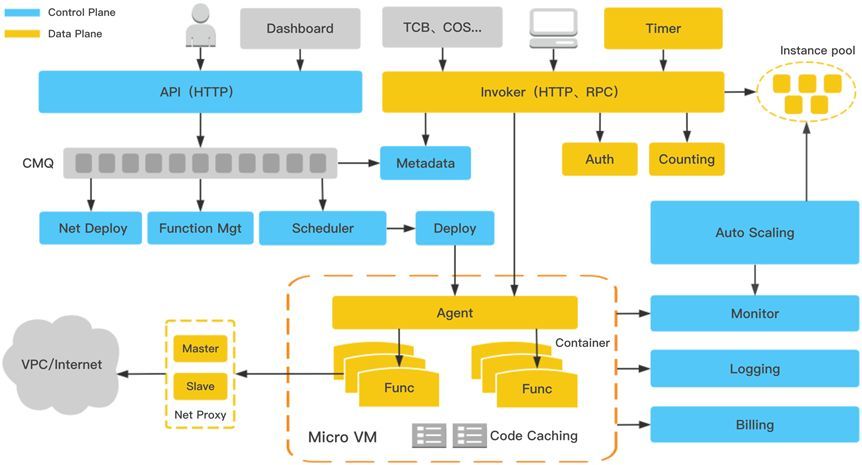
基于以上的一些需求和挑战,我们在控制流和数据流的模块、虚拟化层、网络层、调度层都做了彻底的重构优化,
1、控制流、数据流模块按照职责重新梳理解耦
如上图所示,蓝色的是控制流部分,对函数的生命周期进行管理,API层提供管理的接口,元数据记录数据库后,下发一份到消息系统,通过消息队列解耦后续的管理模块。比如创建函数的场景,网络部署模块接收到消息后,负责打通函数访问VPC资源的转发路径。
函数代码管理模块负责进行代码的检查,依赖安装,重新打包到代码仓库以便后续下载部署。调度模块可以做一些资源预创建,实例预部署的工作,元数据模块负责将管理流的数据同步到数据流的缓存系统,以便后续函数调用时使用。
这样API不需要关注函数管理的底层细节,控制流和数据流也不会干扰。
2、计算层实现了轻量级虚拟化的方案
函数实例节点从传统的虚拟机切换到轻量级虚拟机系统,提高虚拟机的并发部署的规模和速度,同时也实现多租户间的安全隔离,后面会详细介绍。
3、Auto scale自动扩缩容模块
基于函数请求实时计算的模式,动态的扩缩函数实例,优化函数冷启动的体验问题,以及控制函数计算平台本身的成本
4、VPC网络转发代理
函数通常需要访问VPC网络内的存储资源或者访问公网,涉及到网络路径的打通,目前普遍的方式是通过绑定弹性网卡和部署NAT网关达到这个目的,在函数实例部署的过程中耗时占比很大,后面李艳博同事会详细介绍腾讯云函数如何优化这个问题。
函数冷启动优化实践
介绍了腾讯云函数的架构之后,接下来详细看下云函数冷启动相关的问题和优化思路。
函数冷启动就是指函数第一次调用时平台部署函数实例的过程。不单止函数计算,也许万事都有冷启动。比如TCP通信之前的三次握手,HTTPS访问的初始安全验证过程等等。
那为什么函数的冷启动在函数计算这里受到了大家的普遍关注,函数计算平台也在不断优化这个问题呢?
主要有2个原因:
- 其一是用户预期,云函数和本地函数的调用是不一样的,本地函数调用时函数是随时调用都能立刻响应的,不会有明显的时延问题,而云函数需要部署计算环境,而这个部署的过程从数百毫秒到数秒的时间不等,对于对时延敏感的场景,甚至会导致首次调用的超时;
- 第二个原因是正函数平台本身非常弹性扩缩的特点,在调用量下降时会进行资源的回收清理,在下次调用量增长时会再次遇到冷启动,因此冷启动是个反复的过程,伴随在业务运行的整个生命周期里边。
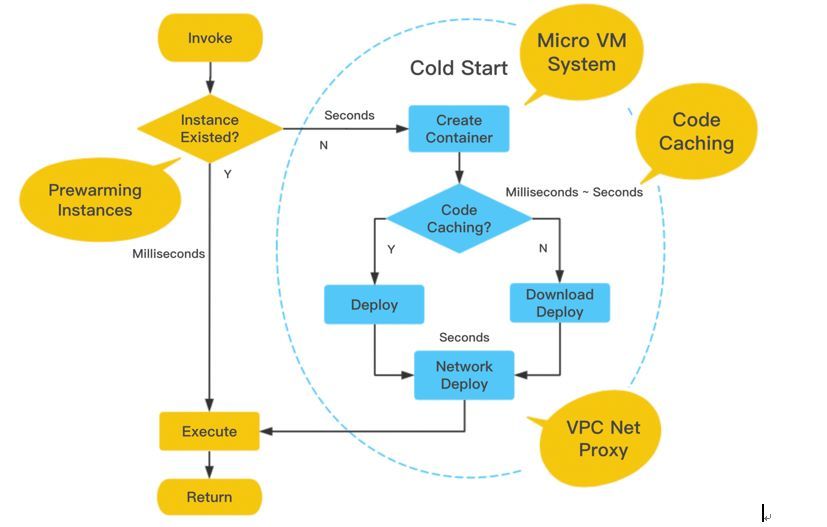
从流程图可以看出函数冷启动包含了哪些过程。黄色的路径是函数实例已经存在的热调用情况,复用了函数实例,热调用的延时是毫秒的级别。如果没有可服用的实例就会走到右边蓝色部分的冷启动过程。
冷启动耗时大头主要是以下三方面:
- 虚拟机和容器的创建过程,传统的虚拟机创建通常需要分钟的级别,容器需要秒的级别
- 函数代码的下载过程,主要取决于代码的大小,下载耗时从几十毫秒到几秒不等
- VPC网络的打通过程,主要是部署弹性网卡和路由下发的过程,通常耗时秒级别
接下来会从轻量级虚拟机系统的优化、代码缓存、VPC转发proxy、实例预创建等几个方面分别介绍优化的结果。
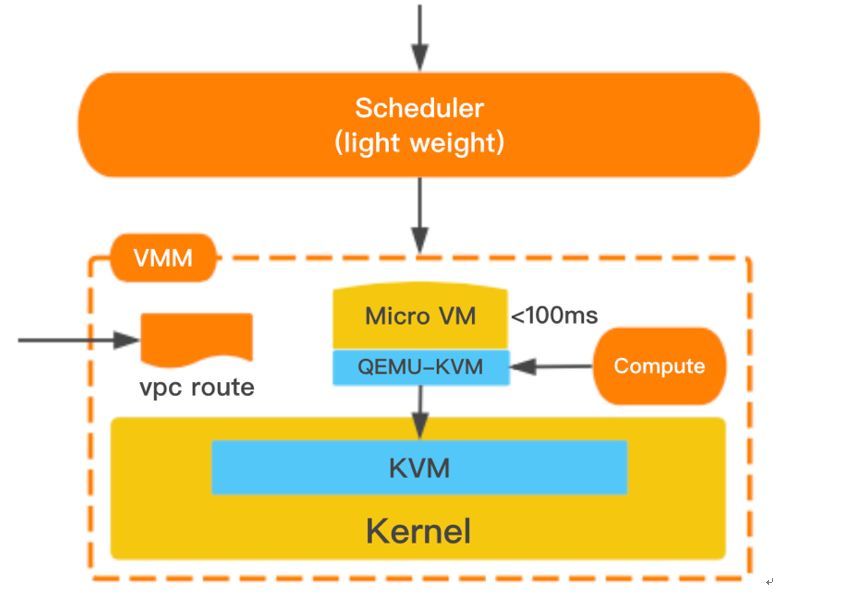
首先是轻量级虚拟机系统的优化,基于腾讯云已有的CVM系统,主要优化资源调度模块以及底层虚拟化层面的耗时。提升资源调度的并发计算和耗时,进行虚拟化层面的裁剪极大的降低了虚拟机启动的时间,虚拟机隔离,访问的策略也通过预同步的方案,降低网络的生效时间。
虚拟机调度这块,如果要全局考虑最优的调度,要考虑的因素是非常多的,比如满足非常多样化虚拟机配置的调度,CPU亲和性和反亲和性的调度,容灾部署组的调度,物理资源的利用率最大化等等,我们看了下现有系统的调度决策的因素多大20种以上,因此规模比较大的时候调度耗时秒级别。
在函数的场景下按照函数运行的配置规格统一了虚拟机标准化配置,比如CPU的型号配置,内存大小,存储的配置和类型等,另外就是对可用的物理机资源进行了离线的计算排序,在调度的时候直接按顺序匹配即可,这样能讲调度物理机的操作时延降低到毫秒级。
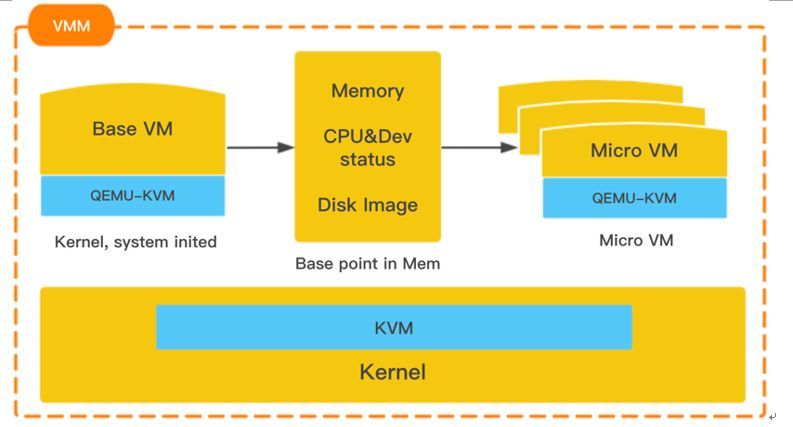
接下来是虚拟化层面,传统的qemu/kvm虚拟机启动到机器可用的时间通常是分钟级别,业界的kata,firecracker的方案是对qemu,虚拟机镜像做裁剪来加速虚拟机的创建和启动,腾讯云虚拟化团队也使用了类似的方案,但是还做了进一步的优化。
在物理机上面,首先制作一台基础的虚拟机完成操作系统、相关内核模块、驱动以及部分用户态组件的初始化,然后将虚拟机的内存状态,CPU寄存器等信息保存到共享内存中,完成虚拟机模版的制作,也就是图中的Basepoint。
后面需要创建轻量级虚拟机时,通过虚拟机模版直接克隆出来运行,通过类似本地热迁移的方式,然后需要把虚拟机内部关于mac,ip,hostname等唯一信息修改过来。
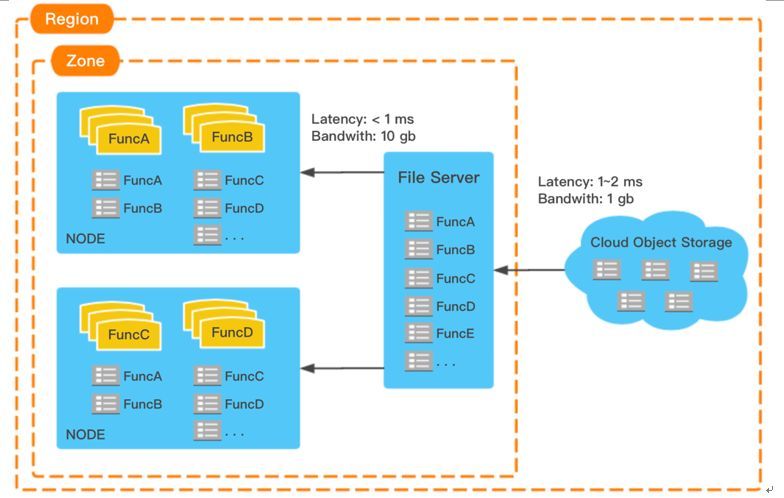
代码下载是冷启动另一个耗时比较大的环节,根据代码包大小不一样,耗时从几十毫秒到几秒都有可能。腾讯云函数这里对代码做了两级的缓存,第一级是虚拟机本地缓存,同一个租户的所有函数全量缓存到虚拟机上,保证了所有函数即使之前没调用过,在第一次调用的时候避免了下载。第二级缓存是可用区内部的缓存,一个可用区内的时延在网络建设标准要求中是1~2毫秒,因此我们将同一个地域的代码全量缓存到各个可用区,保证代码能在可用区内能下载到,降低下载的时间。
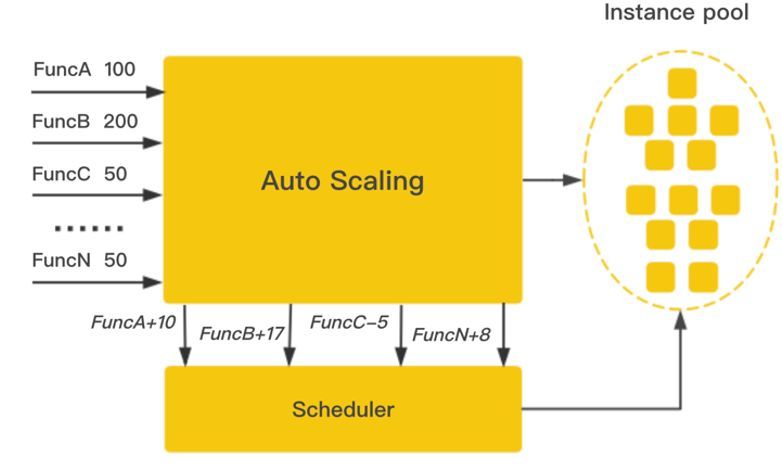
前面分享的优化方向主要是在降低冷启动时延方面,当然最好的情况是可以提前创建出来避免冷启动。在这方面我们做了一个自动实时扩缩容的系统,通过秒级的函数并发监控数据上报,计算函数并发对资源需求的情况进行函数实例的预创建,或者销毁(成本方面考虑)。
在并发预测这块我们尝试了一些方法,包括函数周期性的调用规律数据分析,机器学习等。我们发现函数并发这个维度波动是比较大的,可能会在分钟级别内增长或减少几倍的并发,大体上有按天的周期性的规律,但是并发的波峰波谷产生的时刻偏差比较大,因此最后我们选择了实时计算并快速扩容的方案。
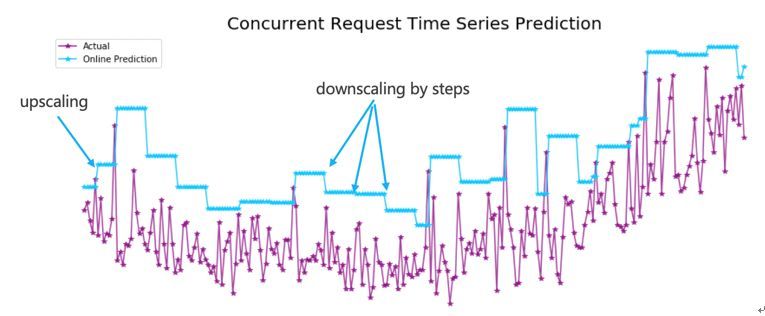
如图中所示,Autoscale模块在监控到函数并发增长的时候,计算出需要扩容的实例数,调用scheduler模块快速部署实例满足后续的并发增长。在缩容的时候有一个冷却时间放置期间有频繁的并发波峰波谷交替出现,当经过冷却时间后进行逐级的缩容。从我们实际的运行效果数据来看,几乎已经能避免冷启动的问题了。
两种可预测的提前预启动实例
最后介绍两种可以预测的提前预启动实例的情况,第一种是函数互相调用的场景:
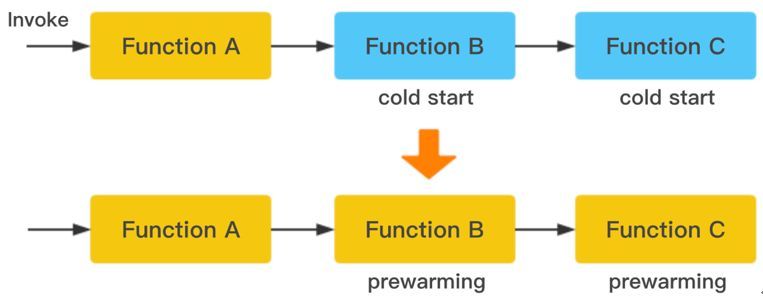
比如图中函数A调用B和C,如果只有函数A预启动了,函数B和C还是冷启动,那最后表现出来就是A函数的调用时延增高。因此平台需要根据函数的调用关系,将被调的函数全路径预启动起来。
第二种情况是函数代码变更和版本切换的场景:
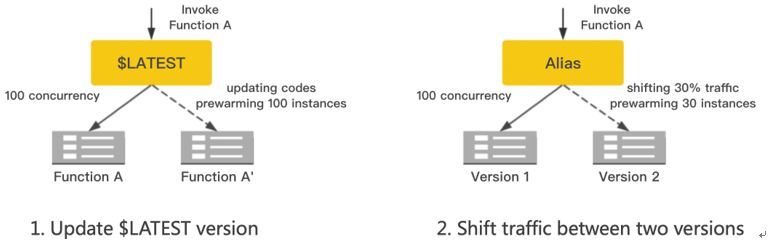
如左边这个函数调用的是LATEST版本,开发者更新代码后,流量不能立刻切换到新的代码,而是需要根据当前并发的情况预先启动一些实例部署新代码后才切换流量,保障调用时延的平滑过度。右边的这个函数是通过别名调用V1版本,如果此时开发者操作切换30%的流量到V2版本,平台需要根据当前并发的情况计算出30%所需的实例个数,将V2的函数实例部署起来才切换流量。