Qwen3.7-Plus作为Qwen3.7系列高性价比旗舰模型,在强大文本能力基础上全面升级视觉-语言能力,同时保留编码、工具调用与生产力工作流的完整智能体能力。其核心特色为多模态交互混合智能体——能够感知真实世界场景、读取并操作GUI界面、基于视觉参考生成代码、端到端导航移动应用。技术参数方面,模型支持1M tokens上下文、单图最高1600万像素、最长2小时视频输入。性能上,文本能力接近旗舰Max,视觉推理BabyVision得分从上代37.4跃升至64.7,Vision Arena榜单跻身全球前五、中国第一。目前已上线阿里云百炼,新人可免费试用100万tokens,推理服务限时8折(输入低至1.6元/百万tokens),广泛适用于图像视频理解、智能体交互、OCR及自动化工作流等高阶场景。
一、Qwen3.7-Plus大模型简介
Qwen3.7-Plus 是阿里云百炼平台推出的千问系列旗舰级多模态大模型,属于 Qwen3.7 系列中的高性能版本,适用于对能力要求高、需处理复杂任务的场景。其核心特性包括:
- 输入模态:支持文本、图像、视频等多种输入类型;
- 上下文长度:高达 1M tokens,适合处理长文档、长视频等复杂输入;
- 最大输出长度:64k tokens;
- 图像处理能力:单图最高支持 1600 万像素(16M),最多可同时输入 2048 张图片;
- 视频处理能力:最长支持 2 小时视频,最大视频大小为 2GB,最多可同时输入 64 个视频;
- 高级功能支持:
- 支持 Function Calling;
- 内置工具(如联网搜索、代码执行),无需额外配置;
- 支持结构化输出(例如从图像中提取 JSON 格式的商品信息)。
在视觉理解任务中,推荐优先使用 qwen3.7-plus,因其具备完整的功能集和最强的综合性能;待业务场景稳定后,可考虑切换至成本更低但效果接近的 qwen3.6-flash。该模型适用于图像分析、视频理解、OCR、智能体交互、多模态推理等高阶应用场景。
Qwen3.7-Plus文本和视觉能力均大幅提升,在第三方权威榜单Vision Arena中跻身全球前五、中国第一。
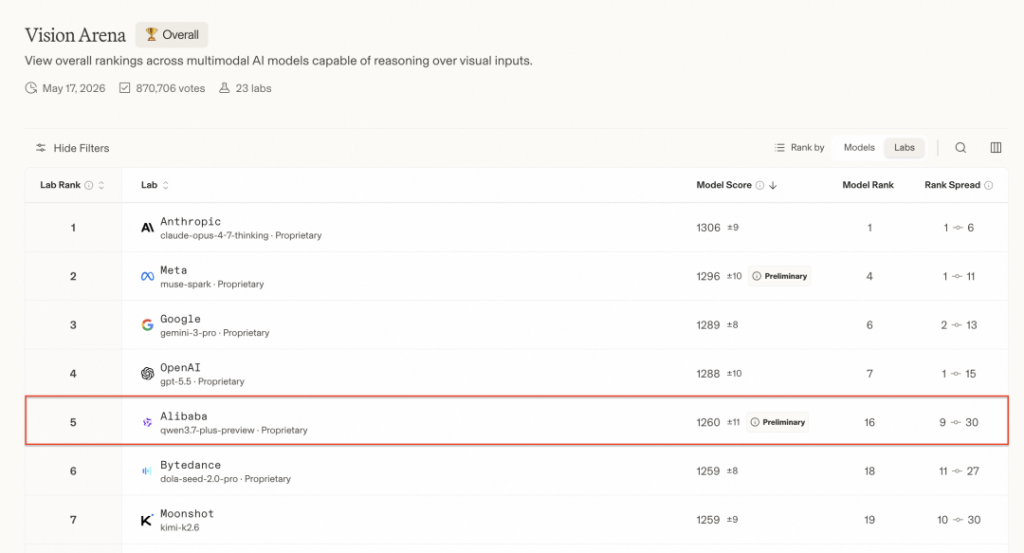
二、Qwen3.7-Plus大模型性能提升参考
Qwen3.7-Plus 的核心特色在于其作为多模态交互混合智能体的能力。它能够感知真实世界场景、读取屏幕并操作 GUI、基于视觉参考生成代码、端到端导航移动应用,以及基于网络知识回答视觉问题——在单一智能体循环中无缝融合 GUI 与 CLI 交互。作为全能型编码智能体与生产力助手,它以全模态输入处理从前端原型到复杂软件工程、再到多步工作流自动化的全方位任务。它具备跨框架泛化能力,无论通过 Claude Code、OpenClaw、Qwen Code 还是其他框架部署,均能保持稳定表现。
1、文本能力接近旗舰,编程与Agent能力显著提升
Qwen3.7-Plus是千问3.7系列的最新模型,纯文本能力可接近旗舰模型Qwen3.7-Max的水平,涌现出Plus级别模型中较强的编程、Agent、推理及通用能力:
- 编程:在Terminal Bench 2.0-Terminus、SciCode等评测中,较上代Qwen3.6-Plus提升约9分Agent:在评估通用Agent能力的Skillbench评测中提升10.2分;在MCP-Mark、Deep-Planning等评测中表现突出。
- 推理:在数学推理Apex评测中,取得近3倍于上代模型的性能评分。
- 长上下文:MRCR-v2 128K得分91.7,长文本理解能力表现优异。
2、视觉能力系统性增强
Qwen3.7-Plus围绕智能体的实际需求,对视觉能力进行了系统性增强:
- 视觉推理:纯视觉推理BabyVision评测得分从上代的37.4提升至64.7,泛化能力大幅提升。
- 搜索增强问答:在SimpleVQA、MMSearchPlus、MMBC等评测中,较上代性能提升最高超2倍。给一张工厂里模糊的专业机械图,千问3.7可以将该设备的功能、参数剖析准确。
- GUI感知与操控:ScreenSpot Pro从上代68.2提升至79.0,AndroidWorld得分81.0,支持理解和操作真实用户界面。
- 视觉编程:从一张照片、截图、草图或一段视频出发,可通过“视觉编程”交付完整的SVG动画或网页。
在视频理解和驾驶场景理解方面,千问3.7对视频中的事件、动作、时序和语义关系,以及真实世界的动态场景、交通参与者和空间关系的理解能力均有增强,为多模态智能体在自动驾驶、具身智能等场景中的应用奠定基础。
3、工具使用能力拓展
集成CI代码解释器后,Qwen3.7-Plus可以将找不同、华容道、迷宫等视觉任务转化为可计算的问题并自主求解。接入搜索增强后,可结合视觉线索与外部知识,回答仅凭图像内容无法解答的开放性问题。
基于 Qwen3.7-Plus 还可以构建浏览器智能助手,面对非科班用户“采购一台最便宜 ECS 服务器”的需求,Agent 能够直接进入云控制台,完成实例规格比价、低成本选型、镜像与存储配置、安全组设置、订单确认等完整操作,并在价格变化、库存限制或购买受阻时主动反思和调整策略。
三、Qwen3.7-Plus适用场景
Qwen3.7-Plus是当前能力最强的多模态模型,推荐在对性能、功能完整性要求高的视觉理解、智能体、自动化工作流等场景中优先使用。 Qwen3.7-Plus适用于以下场景:
- 图像与视频理解:作为千问旗舰模型,支持最高1600万像素的图像输入和最长2小时、2GB大小的视频分析,适合需要高精度视觉理解的任务。
- OCR与文档提取:虽然
qwen-vl-ocr是专为文档优化的模型,但Qwen3.7-Plus也具备强大的通用图文理解能力,可用于复杂文档内容解析。 - Function Calling与内置工具调用:支持根据图像或视频内容执行操作,并内置联网搜索、代码执行等工具,无需额外配置,适用于智能体(Agent)类应用。
- 结构化输出:可从视觉输入中提取结构化JSON数据,例如从商品照片中提取名称、价格等信息。
- 多模态交互混合智能体:能够感知真实世界场景、读取屏幕、操作GUI、基于视觉参考生成代码、端到端导航移动应用,适用于高级自动化与人机交互场景。
- 长上下文处理:支持1M上下文长度和最多2048张图片、64个视频同时输入,适合处理大规模多模态数据。
四、Qwen3.7-Plus大模型支持的订阅计划
Qwen3.7-Plus目前已上线千问云和阿里云百炼平台,支持通过API调用,接受文本和图片/视频双模态输入,兼容OpenAI标准协议。模型支持思维链(enable_thinking)模式,建议在Agent任务中开启。Qwen3.7-Plus 现已通过 阿里云百炼提供服务:
Multimodal Agent:统一处理图像、视频、屏幕、网页和文本输入,并在 GUI / CLI / 工具环境中完成任务
Visual Agent:结合视觉理解、代码解释器和搜索增强,解决视觉谜题、真实世界问答和复杂推理任务
Visual Coding:从图像或视频生成 SVG、网页和交互式前端,实现视觉参考到代码的端到端转化
GUI Agent:理解移动端和桌面端界面,进行控件定位、任务规划和多步操作
Real-world Perception & Reasoning:覆盖真实场景、文档图表、OCR、视频和驾驶场景理解
用户可以通过阿里云百炼大模型服务平台调用:👉https://www.aliyun.com/product/bailian
五、模型表现
1、纯文本测试集
Qwen3.7-Plus 在纯文本能力上表现出色,整体接近 Max 级别模型。在编码 Agent 方面,它在 Terminal Bench 2.0、SWE-bench 系列和 SciCode 上表现强劲,能够有效处理真实软件工程和科学编程任务。在通用 Agent 方面,它在 MCP-Mark、Deep-Planning 和 Kernel Bench L3 上展现了稳健的工具使用与规划能力,在复杂多步规划和 GPU kernel 优化方面尤为突出。其推理能力在 GPQA Diamond、HMMT 和 IMOAnswerBench 上表现优异,在高难度 STEM 基准测试中位于 Plus 级别模型前列。在指令遵循与多语言任务方面,它在 IFBench、WMT24++ 和 PolyMATH 上保持了稳定的高质量表现,覆盖了广泛的语言和领域。
| Opus-4.6 Max | K2.6 Thinking | GLM-5.1 Thinking | DeepSeek-V4-Pro Max | Qwen3.6-Plus | Qwen3.7-Plus | |
|---|---|---|---|---|---|---|
| Coding Agent | ||||||
| Terminal Bench 2.0-Terminus | 65.4 | 66.7 | 63.5 | 67.9 | 61.6 | 70.3 |
| SWE-Verified | 80.8 | 80.2 | -- | 80.6 | 78.8 | 77.7 |
| SWE-Pro | 57.3 | 59.5 | 58.8 | 59 | 56.6 | 57.6 |
| SWE-Multilingual | 77.5 | 76.7 | -- | 76.2 | 73.8 | 75.8 |
| NL2repo | 47.6 | 42.8 | 41 | 35.5 | 34.4 | 41.1 |
| SciCode | 51.9 | 52.2 | 45.1 | -- | 41.4 | 51.3 |
| QwenWebDev | 1617 | -- | 1564 | 1570 | 1500 | 1536 |
| QwenSVG | 1541 | 1325 | 1605 | 1506 | 1432 | 1588 |
| General Agent | ||||||
| Qwenclaw | 65.5 | 54.7 | 58.7 | 59.2 | 57.2 | 61.8 |
| CoWorkBench | 68.2 | 58.2 | 66 | 66.3 | 64.5 | 65.1 |
| ClawEval | 70.4 | 61.5 | 62.7 | 58.4 | 57.1 | 62.7 |
| Skillsbench | -- | 56.2 | 53.1 | 52.3 | 45.7 | 54.9 |
| BFCL-V4 | 76.7 | 71.3 | 70.9 | 70.6 | 68.9 | 72.9 |
| MCP-Mark | 56.7 | 55.9 | 57.5 | 57.1 | 48.2 | 58.7 |
| MCP-Atlas | 75.8 | 66.6 | 71.8 | 73.6 | 74.1 | 73.2 |
| Vitabench | -- | 39.1 | 45.1 | 51.9 | 42.8 | 45.6 |
| Deep-Planning | 58.9 | 42.3 | 34.1 | 44.6 | 40.9 | 62.3 |
| SpreadSheetBench-v1 | 89.3 | 84.5 | 85.2 | 84.9 | 80.2 | 86.3 |
| Kernel Bench L3 | 2.63/98% | 1.41/80% | 2.00/78% | 1.07/54% | 1.03/48% | 2.06/98% |
| QwenWorldBench | 56.1 | 50.9 | 50.2 | 52.3 | 47.6 | 62.1 |
| STEM & Reasoning | ||||||
| GPQA Diamond | 91.3 | 90.5 | 86.2 | 90.1 | 90.4 | 90.3 |
| HLE | 40 | 36.4 | 34.7 | 37.7 | 28.8 | 34.7 |
| LiveCodeBench | 88.8 | 89.6 | -- | 93.5 | 87.1 | 89.6 |
| HMMT 2026 Feb | 96.2 | 92.7 | 89.4 | 95.2 | 87.8 | 92.9 |
| IMOAnswerBench | 75.3 | 86 | 83.8 | 89.8 | 83.8 | 86 |
| CritPT | 12.6 | 8 | 4.6 | 12.9 | 2.9 | 6 |
| Apex | 34.5 | 24 | 11.5 | 38.3 | 8.8 | 22.7 |
| General Capability | ||||||
| MMLU-Pro | 89.7 | 87.1 | 86.3 | 87.5 | 88.5 | 88.5 |
| MMLU-Redux | 95.2 | 95.3 | 94.3 | 94.8 | 94.5 | 94.5 |
| SuperGPQA | 72.5 | 71.3 | 68 | 69.9 | 71.6 | 71.4 |
| IFEval | 91.9 | 94.5 | 94.5 | 91.9 | 94.3 | 94.6 |
| IFBench | 62.5 | 76 | 76 | 77 | 74.2 | 79.1 |
| MRCR-v2(128k) | 84 | 63.1 | 62 | 74.4 | 85.9 | 91.7 |
| Multilingualism | ||||||
| WMT24++ | 82.7 | 81.6 | 81.8 | 82.2 | 84.3 | 84.6 |
| MAXIFE | 81.3 | 87.7 | 87.7 | 88.9 | 88.2 | 88.8 |
| MMMLU | 90.6 | 87.5 | 87.2 | 87.9 | 89.5 | 89 |
| MMLU-ProX | 86.1 | 83.7 | 83.9 | 83.9 | 84.7 | 85.4 |
| NOVA-63 | 59.1 | 56.7 | 54.6 | 52.8 | 57.9 | 58.8 |
| INCLUDE | 87.4 | 84.2 | 84.3 | 86.1 | 85.1 | 83 |
| Global PIQA | 91.2 | 89.2 | 89.5 | 90.5 | 89.8 | 90.3 |
| PolyMATH | 80.2 | 82.7 | 67.6 | 72 | 77.4 | 84 |
2、多模态测试集
Qwen3.7-Plus 的多模态能力提升,不仅是单点视觉理解能力的优化,而是围绕多模态智能体所需的关键能力系统性增强:看懂复杂视觉输入、基于视觉进行推理、调用工具解决问题,并最终在代码或 GUI 环境中执行任务。
在 Multimodal Reasoning 方面,Qwen3.7-Plus 在 BabyVision、MathVision、HiPhO、ERQA 和 VisFactor 等高难度视觉推理基准上取得强表现,体现出对图像细节、空间关系、物理常识和多步逻辑的综合理解能力。尤其在 BabyVision 上,相比 Qwen3.6-Plus 有显著提升,说明模型在更接近人类早期视觉认知和空间推理的任务上具备更强泛化能力。
在 Visual Agent & Coding 方向,Qwen3.7-Plus 在 ScreenSpot Pro、OSWorld-Verified 和 AndroidWorld 上显著提升,说明模型不仅能够识别屏幕内容,还能够定位关键 UI 元素、理解任务意图,并完成多步交互操作。在 QwenVision2Code 上,模型也展现了强视觉到代码生成能力,能够将图像、视频和设计参考转化为可执行代码。这类能力是多模态智能体从“看懂界面”走向“操作界面”和“构建界面”的基础。
在 Multimodal Search & Knowledge QA 方面,Qwen3.7-Plus 在 SimpleVQA、WorldVQA、MMSearchPlus、BC-VL 和 MMBC 上均有明显增强。模型可以将视觉输入与外部知识检索结合起来,回答单纯依赖图像内容无法完成的问题。这使它更适合真实世界任务:用户不只是问“图里有什么”,而是希望模型结合图像、常识和最新知识给出可靠答案。
在 General Visual Understanding 方面,Qwen3.7-Plus 覆盖真实世界场景、文档解析、图表阅读、OCR、计数和空间定位等基础能力,在 RealWorldQA、CountQA、OmniDocBench、CharXiv、OCR-Bench-V2 等任务上保持强表现。这些能力决定了模型能否稳定处理真实业务输入,包括截图、票据、表格、报告、海报、商品图和复杂 UI 页面。
此外,Qwen3.7-Plus 进一步增强了 视频理解和驾驶场景理解。在 VideoMMMU、MLVU、TVBench、LVBench 等视频任务上,它能够处理短视频和长视频中的事件、动作、时序和语义关系;在 LingoQA、Ego3D-Bench、SURDS 和 VLADBench 等驾驶相关评测中,也展现出对动态场景、交通参与者和空间关系的强理解能力。这为真实世界多模态智能体、自动驾驶理解和 embodied 场景打下了基础。
| GPT-5.4 (xhigh) | Opus-4.6 Max | Gemini-3.1 Pro | Qwen3.6-Plus | Qwen3.7-Plus | |
|---|---|---|---|---|---|
| Multimodal Reasoning | |||||
| MMMU-Pro | 81.2 | 73.9 | 81.8 | 78.8 | 79 |
| MathVision | 91 | 65.5 | 87.4 | 88 | 90.3 |
| BabyVision | 53.1 | 12.6 | 55.9 | 37.4 | 70.4 / 64.7 |
| CharXiv(RQ) | 84.5 | 66 | 84.4 | 81.5 | 85.9 / 84.4 |
| HiPhO | 65 | 40.8 | 85.4 | 80.4 | 84.1 |
| ERQA | 67.8 | 40.8 | 68 | 65.7 | 69.8 |
| VisFactor | 40.8 | 24.4 | 39.8 | 36 | 42.8 |
| MedXpertQA-MM | 77.3 | 64.4 | 80.7 | 68.7 | 71 |
| Visual Agent & Coding | |||||
| ScreenSpot Pro | 67.4 | 49.5 | 68.1 | 68.2 | 79 |
| OSWorld-Verified | 75 | 72.7 | -- | 62.5 | 73.3 |
| AndroidWorld | -- | 62 | 70.7 | 67.2 | 81 |
| QwenVision2Code | 1884 | 1518 | 1632 | 1522 | 1772 |
| ClawEval-MM | 54.4 | 54.7 | 45.7 | 49.1 | 55.7 |
| Multimodal Search & Knowledge QA | |||||
| SimpleVQA | 69.4 | 79.6 | 76.9 | 69.4 | 81.7 |
| WorldVQA | 45.9 | 65.4 | 56.1 | 33.6 | 61.1 |
| MMSearchPlus | 19.7 | 38.9 | 42 | 19.6 | 41.4 |
| BC-VL | 48.1 | 51.5 | 49.9 | 26.1 | 51.1 |
| MMBC | 18.8 | 46.3 | 28.2 | 18.3 | 46.3 |
| General Visual Understanding | |||||
| RealWorldQA | 83.8 | 73.9 | 83.5 | 85.4 | 86.9 |
| CountQA | 58.4 | 32.5 | 72.8 | 71.7 | 77 |
| OmniDocBench1.5 | 85.5 | 86.6 | 90 | 91.2 | 91.4 |
| OCR-Bench-V2(EN) | 59.1 | 54.3 | 64.6 | 67 | 70.7 |
| OCR-Bench-V2(ZH) | 57.7 | 54.9 | 58.2 | 63.6 | 67.1 |
| ODinW13 | -- | -- | -- | 51.8 | 51.1 |
| Autonomous Driving | |||||
| LingoQA | 78.2 | 77.6 | 66.8 | 76 | 83.4 |
| Ego3D-Bench↓ | 6.9 | 8.1 | 10.4 | 6.1 | 5.9 |
| SURDS | 64.6 | 58.3 | 64 | 73.2 | 77.2 |
| VLADBench | 77.1 | 48 | 73.1 | 75.6 | 77.2 |
| Video Understanding | |||||
| VideoMME (w/ sub.) | 89.5 | 86.1 | 88.4 | 87.8 | 88 |
| VideoMMMU | 82.4 | 85.2 | 85.3 | 84 | 85.4 |
| MLVU (M-Avg) | 86.1 | 81.7 | 84.7 | 86.7 | 87.4 |
| TVBench | 82.5 | 69.8 | 73 | 76 | 78.2 |
| LVBench | 77.4 | 63 | 75.1 | 74.8 | 76.2 |
六、Qwen3.7-Plus 体验步骤
1、开通阿里云百炼
开发兼容、灵活配置、高性价比的企业级大模型服务平台,助力轻松构建 AI 应用。
2、免费试用 100 万 tokens
深度体验智能体能力的广度与深度和出色的跨框架泛化能力,新人免费额度有效期为 90 天。
3、限时8折
能感知真实世界场景、操作图形界面、基于视觉参考编写代码,并在 GUI 与 CLI 环境中端到端完成任务。目前Qwen3.7-Plus 推理服务 后付费限时8折,详情可参考:👉https://www.aliyun.com/benefit/scene/qwen37plus
具体价格如下表所示:
| Qwen3.7-Plus | 输入<=256k | 256k<输入<=1m | ||
|---|---|---|---|---|
| 折后 限时8折 | 官网价 | 折后 限时8折 | 官网价 | |
| 输入 | 1.6元/每百万tokens | 2元/每百万tokens | 4.8元/每百万tokens | 6元/每百万tokens |
| 输入(缓存命中) | 0.32元/每百万tokens | 0.4元/每百万tokens | 0.96元/每百万tokens | 1.2元/每百万tokens |
| 显式缓存创建 | 2元/每百万tokens | 2.5元/每百万tokens | 6元/每百万tokens | 7.5元/每百万tokens |
| 显式缓存命中 | 0.16元/每百万tokens | 0.2元/每百万tokens | 0.48元/每百万tokens | 0.6元/每百万tokens |
| 输出 | 6.4元/每百万tokens | 8元/每百万tokens | 19.2元/每百万tokens | 24元/每百万tokens |
附:阿里云最新AI 产品优惠权益
AI 产品权益主要包括阿里云百炼 Token Plan,提供多档位套餐,包月预算可控;HappyHorse-1.0 系列模型 限时 8 折;阿里云百炼 Token Plan,提供多档位套餐,包月预算可控;Qwen3.6全模型通享 4.5 折;Qwen3.7-Max 发布,限时5折起;阿里云百炼优惠券,先用后返,最高200元,个企同享;阿里云 JVS Claw 39元起,一键接入 OpenClaw等。详情可通过阿里云权益中心了解:👉https://www.aliyun.com/benefit
购买之前建议先了解一下当下是否有优惠券或者代金券可以领取,2026年,阿里云官方已经通过云小站平台:👉https://www.aliyun.com/minisite/goods 推出云产品通用折扣优惠券,先领券再购买,价格可以在优惠价格基础上额外获得一个折扣优惠,最高能减12500元。
小结:Qwen3.7-Plus作为千问系列当前能力最强的多模态模型,核心优势在于将视觉理解、GUI操作、代码生成与智能体规划融为一体,真正实现了从"看懂"到"操作"再到"交付"的完整能力。文本能力接近旗舰Max,视觉推理BabyVision得分较上代提升近一倍。无论是复杂文档解析、多步工作流自动化,还是端到端移动应用导航,均能稳定胜任。目前已上线阿里云百炼,新人可免费试用100万tokens,推理服务限时8折,是当前高性价比的多模态智能体首选。